In the above problems, the hypothesis space $\mathcal{H}$ plays an important role. Consider, in a supervised setting, the function $f$ such that $f(\mathbf{x})=\mathbf{y}$ for $(\mathbf{x},\mathbf{y})\in\mathcal{D}$ and $g(\mathbf{x})=0$ otherwise. Clearly if $f$ is in $\mathcal{H}$, it is optimal for any classification or regression problem according to Definitions [def:classification-problem] and [def:regression-problem]. However, this function is not a desirable solution. Indeed, if a model is trained using examples $(\mathbf{x},\mathbf{y})\in\mathcal{D}$, the objective is not to have a model that performs well only on these given examples. Instead, we want a model to generalize from the examples in the dataset, and give accurate values $\mathbf{y}$ for unseen points $\mathbf{x}$ which were not used during training.
Consequently, the hypothesis space should not contain functions such as the one presented above where the points in the dataset can be learned exactly at the expense of generalization, but should represent a hypothesis on the form of possible solutions by containing only functions which have a credible behavior. A common hypothesis for instance is that of smoothness, i.e. $f$ is assumed to have similar values for inputs which are close to each other.
When a model matches the training examples too closely at the expense of generalization, it is said to be over-fitting. Over-fitting results from having a hypothesis space too big for the dataset and containing spurious functions such as the one given above. Conversely, when the hypothesis space is too small and a model is unable to capture important variations of the dataset, we say that the model is under-fitting.
It seems important to point out that learning without generalization is just a method for storing information and therefore, is not learning at all: the purpose of learning is generalization. Accordingly, we cannot assess performance from the loss on the training dataset which can be arbitrarily low when the hypothesis space is too big: we must use an other disjoint dataset. Thus, it is usual to have two datasets: a training set on which to minimize the loss during training, and a disjoint testing set to evaluate the final performance of a trained model. The figure below gives an account of how training error and testing error are expected to vary when model complexity increases.
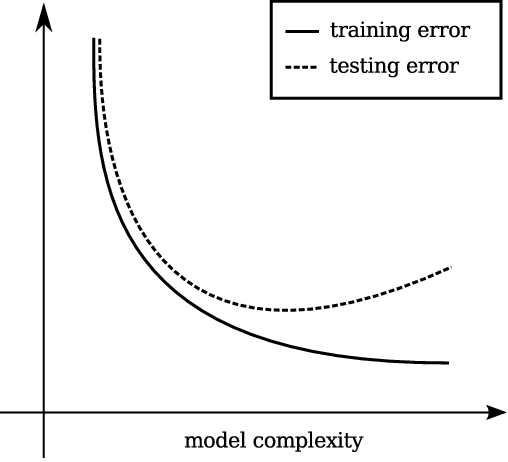
Figure 1: Expected variation of the training and testing error with increasing model complexity.